Contrastive Multi-View Representation Learning on Graphs
一、相关工作
Random walks
Graph kernels
Graph auto encoders (GAE)

Deep graph Infomax(DGI)
自编码器

互信息(MI, mutual information)




二、模型组件


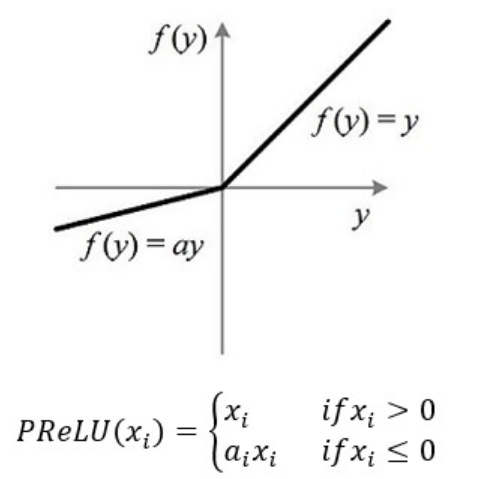




三、解决方法
广义图传播(diffusion)

两种图传播算法的实例(卷积?)

子采样
四、总结
最后更新于