心理学随机森林
摘要
用机器学习(即随机森林):
量化关系质量的可预测程度
确定哪些结构可以可靠地预测关系质量。
关系质量的最高预测因子是:(RF里的重要性?)
感知伴侣承诺
欣赏
性满足
感知伴侣满意度
冲突
个体差异最大的预测因子:(方差?)
生活满意度
消极情绪
抑郁
依恋回避
依恋焦虑
??特定于关系的变量在基线时预测的方差高达45%,在每个研究结束时预测的方差高达18%。
Overall, relationship-specific variables predicted up to 45% of variance at baseline, and up to 18% of variance at the end of each study.
??个体差异和伴侣报告除了行为人报告的关系特异性变量外,没有预测效果。
Importantly, individual differences and partner reports had no predictive effects beyond actor-reported relationship- specific variables alone.
结论:
所有个体差异和伴侣经验的总和通过一个人的特定关系经验对关系质量产生影响,并且由于个体差异的调节和伴侣报告的调节而产生的影响可能很小。
??最后,通过任何自我报告变量的组合,发现关系质量的变化(即,在研究过程中关系质量的增加或减少)在很大程度上是不可预测的。
意义
什么能预测人们对他们的浪漫关系有多幸福?
已经确定了数百个据称影响浪漫关系质量的变量。目前的项目使用机器学习来直接量化和比较11196对浪漫夫妇中许多这样的变量的预测能力。
人们对关系有自己的判断,比如他们对伴侣的满意程度和忠诚程度,感激程度,解释了他们目前满意度的45%。
这些变量并没有增加信息,都无法预测谁的关系质量会随着时间的推移而增加或减少
附件
数据征集策略
来自每对情侣的浪漫伴侣的数据
从至少相隔2个月的至少两个时间点收集的数据
在每个时间点收集的关系满意度的测量值
分析策略
机器学习
同时处理多个变量,最小化过拟合
建立分类树和回归树
随机森林方法使用一个随机的预测器和参与者子集,通过一个称为递归分区的过程,一次一个地测试每个可用预测器的强度。
选择最好的预测器构建决策树,并在未使用的数据上测试预测能力
分别产生了数千个决策树,然后使用平均值结合在一起。
结果
??依赖性测试中多少方差是可预测的。
哪些变量对模型的贡献度大
举例能够预测非线性关系:
For example, a model with actor- and partner-reported predictors would detect any robust actor × partner interactions (e.g., moderation, attenuation effects, matching effects) that could not be captured in a model featuring actor- or partner-reported predictors alone.
参数设置:
ntree = 5000,树的数量
mtry = 1/3,每个节点上可用于拆分的预测因子数量
R语言中的VSURF包:An R Package for Variable Selection Using Random Forests Robin Genuer
输出:
每个模型都显示了模型解释的总方差量,以及作为预测变量的具体变量
模型设置:
对每个数据集进行了21个随机森林模型,
满意度为因变量
7个预测基线满意度,
7个预测后续满意度
7个预测满意度变化
类似地,我们对每个包含忠诚的数据集(即我们的次要因变量)进行了21个随机森林模型,每个数据集总共有42个随机森林模型(最大值)。
总共有43个数据集,每个数据集最大42个模型
每个数据集的结果在 https://osf.io/4pbfh/
元分析
42个模型中的每一个都作为一个??单独的随机效应元分析进行了检验;
21个满意度荟萃分析分别包含k=43个效应量(effect sizes),每个数据集对应一个21个满意度模型
21个忠诚度元分析每个包含k=31个效应量。有31个数据集有忠诚数据,每个数据集对应一个21个忠诚度模型
我们使用综合荟萃分析进行基本分析。
为了计算每个效应量,我们将随机森林模型结果的“方差占比”转换为效应大小r(通过取平方根);
??方差占比==特征重要性
不纯度(impurity)在分类中通常为Gini不纯度或信息增益/信息熵,对于回归问题来说是方差。
概率越大,纯度(或熵)越小 ,即发生的不确定性越小
然后我们进行Fisher-zr变换,我们使用N-3作为逆方差权重,其中N等于随机森林中使用的观察数分析
??参考论文31,32
z' = 0.5 * ln((1+z)/(1-z))
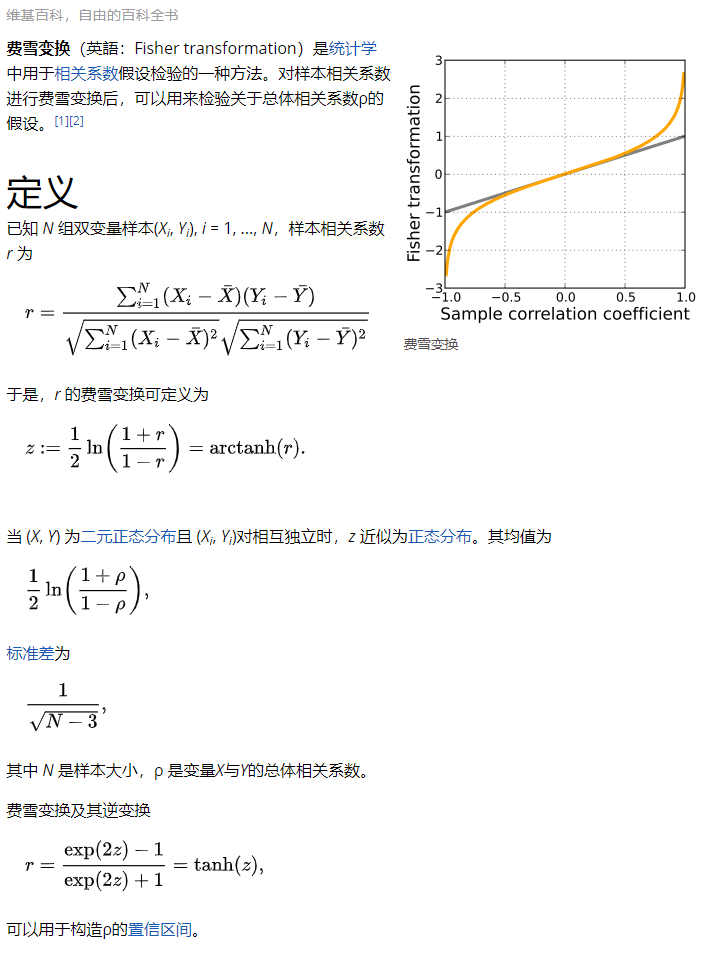
我们将meta分析的结果转换回结果中占百分比的方差(通过将值平方)
满意度和忠诚度的元分析数据文件在https://osf.io/v5e34/。
调节分析Moderation Analyses
分析12种可能的元分析调节因子,
10个是数据集的特征:研究长度、时间点之间的长度、时间点的数量、样本的平均关系长度、样本的平均年龄、开始收集数据的年份、国家、出版状态(至少有1个出版物与未出版过的文献)、样本类型(社区与大学生)、关系状况(约会vs.已婚)。
2个是元分析数据特有特征:
随机森林模型中预测因子的数量
VSURF在最终模型中选择的预测因子的数量
使用了SPSS宏指令,表现调节分析.
结果
初步荟萃结分析结果Primary Meta-Analytic Results
元分析调节Meta-Analytic Moderators
预测限制效应Predictor Restriction Effects
具体结构的预测成功Predictive Success of Specific Constructs
总结
两个问题:
什么能预测我对我的伴侣会有多满意和忠诚
答案:
负面影响、抑郁或不安全的依恋肯定是关系的危险因素
如果人们设法建立起一种以欣赏、性满足和较少冲突为特征的关系,并且他们认为他们的伴侣是忠诚的和有反应的,那么这些个人的风险因素可能无关紧要。
关系质量可以从各种结构中预测,但有些结构比其他结构更重要,而最接近的预测因素是表征一个人对关系本身感知的特征。
最后更新于