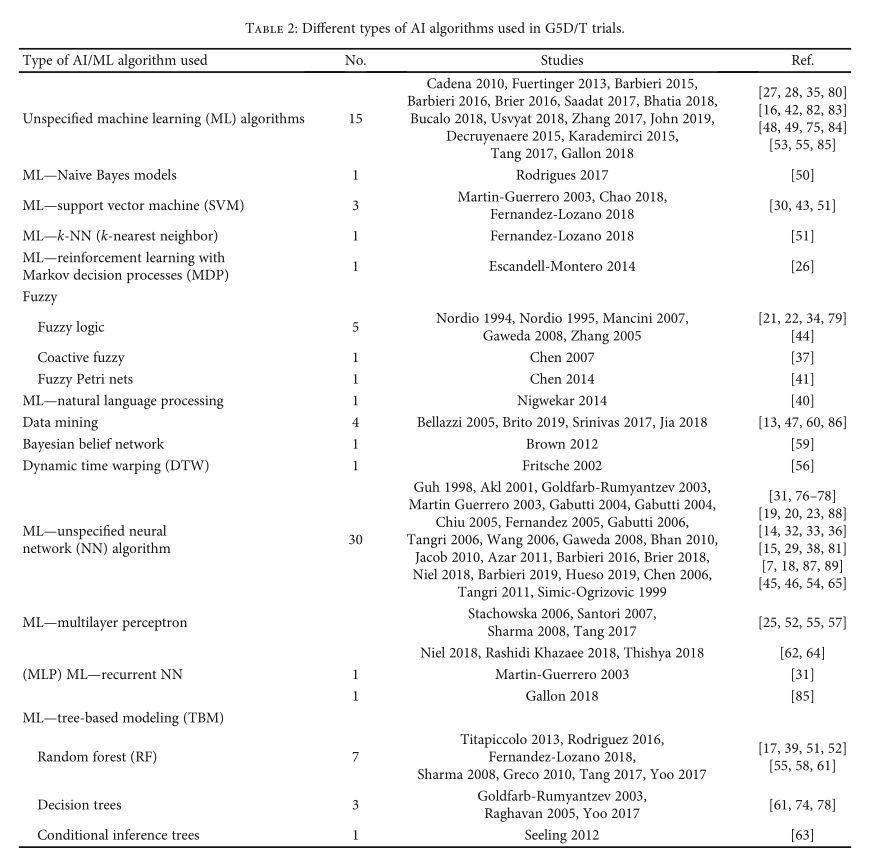
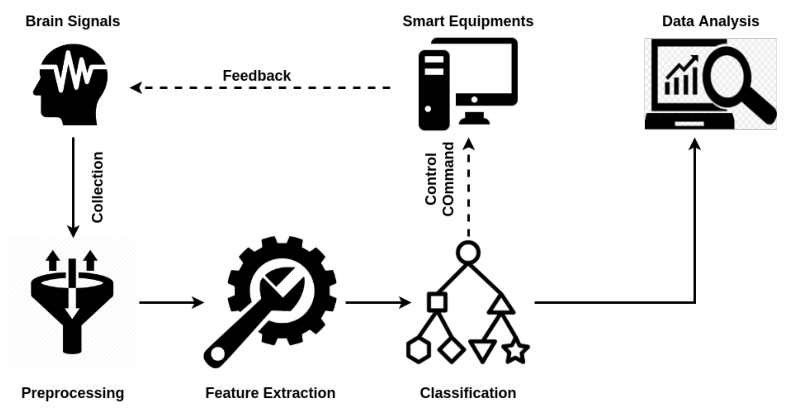
工作流程包括几个关键部分:脑信号采集、信号预处理、特征提取、分类和数据分析
头骨让信号保真度为5%(以信噪比(SNR)衡量)
预处理:包含多个步骤,如信号清理(平滑噪声信号或解决不一致性)、信号标准化(沿时间轴对每个信号通道进行标准化)、信号增强(去除直流电)和信号压缩(呈现信号的简化表示)。
分类结果应用:神经疾病诊断、情绪测量和驾驶疲劳检测。
脑机接口的深度学习的分类:
传统BCI所面临的挑战:
大脑信号很容易被各种生物因素(如眨眼、肌肉伪影【肌肉产生的电波对脑电波的影响】、疲劳和注意力集中程度)和环境因素(如噪音)所破坏
深度学习好处:
深层神经网络和第二层神经网络都能捕获潜在的,具有代表性的特征。
综述论文贡献:
对非侵入性脑信号论文的全面性调查
功能性近红外光谱(functional near - infrared spectroscopy , fNIRS)【利用血液的主要成分对600-900nm近红外光良好的散射性,从而获得大脑活动时氧合血红蛋白和脱氧血红蛋白的变化情况,产生功能性神经影像】
综述论文内容:
讨论了流行的深度学习技术和最新的脑信号模型,为在给定特定信号亚类的情况下选择合适的深度学习模型提供了实用指南。
回顾了基于深度学习的脑信号分析的应用,并指出了一些有前景的未来研究课题。
基于信号收集方法的非侵入性脑信号分类(虚线不调查)
P300包含于ERP中。
ERP:一种特殊的脑诱发电位,通过有意地赋予刺激以特殊的心理意义,利用多个或多样的刺激所引起的脑的电位。它反映了认知过程中大脑的神经电生理的变化,也被称为认知电位,也就是指当人们对某课题进行认知加工时,从头颅表面记录到的脑电位。
其他脑成像技术(fNIRS,fMRI)中的视觉/听觉任务未曾有采用过深度学习,但理论上可行。
第三节,概述常用的深度学习模型
分类模型:Multi-Layer Perceptron (MLP) , Recurrent Neural Networks(RNN) , Convolutional Neural Networks (CNN) --> 特征提取和分类
表示模型:Autoencoder(AE), Restricted Boltz-mann Machine (RBM) , Deep Belief Networks(DBN) --> 只能特征提取
生成模型:Variational Autoencoder (VAE),Generative Adversarial Networks (GANs) --> 主要用于生成脑信号样本,增强训练集
各个非侵入式脑信号特征:
第四节,最先进的脑信号深度学习技术
4.1.1.1 睡眠脑电:
主要用于识别睡眠阶段、诊断睡眠障碍或培养健康习惯
睡眠阶段包括清醒、非快速眼动1、非快速眼动2、非快速眼动3、非快速眼动4和快速眼动。
美国睡眠医学学会(AASM)建议将睡眠分为五个阶段:清醒、非快速眼动1、非快速眼动2、慢波睡眠(SWS)和快速眼动。
识别睡眠阶段,一般通过滤波器实现脑电信号的预处理,数据通常是30s的窗口,50hz。
分类模型:CNN用于单通道EEG的睡眠阶段分类,86%精确度
表示模型:DBN-RBM(深度置信网络-受限玻耳兹曼机)从睡眠脑电信号中提取功率谱密度(PSD,表示随机信号的强度),在局部数据集达到F-1值92.78%(兼顾召回率和精确度)
4.1.1.2 运动想象脑电:
深度学习在运动想象脑电图和真实运动脑电图的分类上显示出优越性
分类模型:大多使用CNN来识别脑电图,例如:
从EEG信号中学习情感信息,构建改进的LSTM控制智能家电
4.1.1.3 情绪脑电图
个体的情绪可以从三个方面来评价:评价值(积极感情的值)、唤起度(激动的程度)和控制力。
这三个方面的结合形成了恐惧、悲伤和愤怒等情绪,这些情绪可以通过脑电图信号来揭示。
分类模型:传统上使用MLP,CNN和RNN正在越来越流行
通过多通道脑电信号转化为二维矩阵来捕捉通道之间的空间相关性
4.1.1.4 精神病脑电图
大量研究人员利用脑电图信号诊断神经系统疾病,特别是癫痫发作
分类模型:CNN广泛应用于癫痫发作的自动检测
CNN对癫痫发作的高通量(1hz)EEG信号进行研究,获得了94.7%的AUC
在抑郁症检测上采用了13层CNN模型,在30名受试者的局部数据集上进行了评估,基于左半球和右半球EEG信号的准确率分别为93.5%和96.0%
4.1.1.5 数据增强
实验1:EEG信号转换为图像
首先证明了脑电波中包含的信息被赋予了区分视觉对象的能力
然后使用RNN提取了更健壮、更具区分性的脑电数据表示。
最后,利用GAN范式训练了一个由学习的EEG表示调节的图像生成器,该生成器可以将EEG信号转换为图像
实验2:将EEG信号转换为图像
当受试者观察屏幕上的图像时,采集脑电图信号。将脑电信号的潜在结构作为输入,提取脑电信号的潜在特征。
GAN的产生器和鉴别器均由卷积层构成。该发生器根据训练后的脑电信号生成图像。
实验3:癫痫发作数据增强的GAN(生成式对抗网络)
作者证明了GAN优于其他生成模型,如AE和VAE(可变自动编码器)。增强后,分类准确率从48%提高到82%。
4.1.1.6 其他
实验1:听觉/视觉刺激(持续存在的刺激)如何影响脑电图信号
13名受试者受到23种节律性刺激的刺激,其中包括12种东非和12种西方刺激。
对于24类分类,提出的CNN平均准确率为24.4%。
之后,作者利用卷积AE进行表征学习,CNN用于识别,12类分类的准确率达到27%
实验2:区分是在听歌还是想象歌曲
提出两个深度学习模型,使用二值分类任务,所提出的CNN和DBN-RBM(三个RBM)的准确率分别为91.63%和91.75%。
实验3:自发脑电图可以用来区分使用者的心理状态(逻辑与情绪)
实验4:认知负荷(处理具体任务时加在学习者认知系统上的负荷)或体力负荷对EEG的影响
实验5:在不同心理负荷下,受试者之间及受试者本身中的一般特征是恒定的。
脑电信号经低通滤波器滤波后,转换到频域,计算功率谱密度(PSD)。
提取的PSD特征被输入到去噪D-AE结构中,以便于进一步的细化。最终得到了95.48%的准确率。
实验6:驾驶员疲劳检测 --- 三维CNN
实验7:驾驶员疲劳检测 --- ICA+DBN-RBM
达到85%左右准确率,二分类(“昏昏欲睡”或“警惕”)。
实验8:驾驶员疲劳值检测 --- DBM-RBM+SVM,精度达到73.29%
实验9:调查了不同低负荷水平下驾驶员的心理状态。提出了一种基于脑电信号直接检测驾驶负荷的CNN方法。
实验10:基于EEG信号的眼睛状态(闭或开)的检测
三个RBM的DBN-RBM和三个AEs的DBN-AE,98.9%的高准确率
事件相关去同步(ERD)表示正在进行的EEG信号的功率下降,
事件相关同步(ERS)表示EEG信号的功率增加
实验11:采用CNN在观看特定视频时通过脑电图检测学校欺凌行为。
实验12:结合RNN和CNN提出了一个级联框架来预测个体的情感水平和个人因素(五大人格特征、情绪和社会背景)。
实验13:试图根据使用者的脑电图信号来识别他们的性别
采用标准的CNN算法,在局部数据集上实现了81%的二元分类精度
实验14:驾驶员的脑电图信号可以区分刹车意图和正常驾驶状态
**实验15:**将大脑信号和推荐系统结合起来,通过EEG信号预测用户的偏好。
共有16名受试者接受了60个手镯状物体作为旋转视觉刺激物(3D物体)时采集脑电信号的实验。
然后采用MLP预测用户喜欢或不喜欢。本次勘探的预测精度为63.99%。
**实验16:**试图探索一个可用于各种脑信号范式的共同框架,并评估鲁棒性。基于compact CNN的EEGNet [73]
4.1.2.1 ERP事件相关电位
在大多数情况下,ERP信号都是通过P300现象来分析的。
4.1.2.1.i VEP视觉诱发电位
较热门。
实验1:通过深度学习提取具有代表性的特征来研究运动开始的 VEP(mVEP)
压缩后的信号被发送到DBN-RBM算法中,以获取更抽象的高层特征。
实验2:P300信号特征提取
通过带通滤波器(2∼35hz)过滤视觉刺激的P300信号,
该模型包括一个2D CNN来捕获空间特征,然后在LSTM层中进行时间特征提取。
实验3:使用AE模型进行特征提取,然后使用支持向量机分类器。
实验中,每一段包含150个点,分为五个时间步,每一步有30个点。
实验4:DBN-RBM代表性模型与支持向量机分类器相结合进行隐藏信息测试(??),97.3%准确率
实验5:提高P300写字机准确率
一种基于CNN的新模型,该模型包括5个具有不同特征集的低层CNN分类器
第三届BCI竞赛数据集II中,最高准确率达到95.5%
4.1.2.1.ii AEP听觉诱发电位
较少研究。
实验1:提出并测试了18个CNN结构来对单次试验的AEP信号进行分类。
实验分析表明,无论卷积层数多少,CNN框架都能有效地提取时空特征。
4.1.2.1.iii RSVP快速连续视觉表示
CNN和MLP在这里取得一定成功。
实验1:一种针对RSVP的主题间和任务间检测的CNN模型。
实验结果表明,CNN在交叉任务中表现良好,但在跨主题情境下表现不佳。
实验2:比较了三种不同的深度神经网络算法,以预测受试者是否看到了目标。
MLP、CNN和DBN模型的AUC分别为81.7%、79.6%和81.6%。
...
4.1.2.2 SSEP稳态诱发电位
大多数研究稳态视觉诱发电位(SSVEP),指由闪烁的视觉刺激引起的脑震荡,通常产生于顶叶和枕叶。当施加一个恒定频率的外界视觉刺激时,与刺激频率或谐波频率相一致的神经网络就会产生谐振,导致大脑的电位活动在刺激频率或谐波频率处出现明显变化,由此产生SSVEP信号。
实验1:寻找SSVEP的中间表现形式。
提出了一种结合CNN和RNN的混合方法,直接从时域中提取有意义的特征,准确率达到93.59%。
实验2:紧凑CNN直接处理原始结果
实验3:采用了一种典型的稀疏AE模型,从多频视觉刺激中提取SSVEP的不同特征。
该模型采用了一个softmax层进行最终分类,准确率为97.78%。
...
4.2 fNIRS功能性近红外光谱
较少研究。
定义:利用血液的主要成分对600-900nm近红外光良好的散射性,从而获得大脑活动时氧合血红蛋白和脱氧血红蛋白的变化情况,产生功能性神经影像。
实验1:基于fNIRS信号分析了两种心理任务(心算和休息)之间的差异。
从前额叶皮层fNIRS中手动提取了6个特征,并比较了6个不同的分类器。
结果表明,MLP的准确率为96.3%,优于所有传统的分类器,包括SVM、KNN、naivebayes等。
实验2:试图通过fNIRS信号检测受试者的性别。
作者使用三层隐层去噪D-AE来提取显著特征并输入MLP分类器进行性别检测。
该模型在本地数据集上进行了评估,平均准确率为81%
相比fMRI信号,fNIRS具有更高的时间分辨率和更经济的价格
4.3 fMRI功能性磁共振成像
利用磁振造影来测量神经元活动所引发的血液变化。从而监测大脑活动
该领域,近年用了不少深度学习方法,特别是认知功能障碍的诊断上。
分类模型中,CNN是一种很有前途的fMRI分析模型
实验1:根据功能磁共振成像(fMRI)和核磁共振成像(MRI)数据,应用深层CNN识别阿尔茨海默病。
实验2:利用一种新的CNN算法建立了一种基于fMRI的脑肿瘤分割方法,它可以同时捕获全局特征和局部特征
实验3:采用CNN模型处理脑瘤患者的功能磁共振成像(fMRI)进行三类识别(正常、水肿或活动性肿瘤)。在BRATS数据集上对模型进行了评估,得到了88%的F1分数
实验4:利用CNN进行特征提取。提取的特征用支持向量机分类,用于癫痫发作的检测
大量文章证明了表示模型在识别功能磁共振成像数据方面的有效性。
实验1:利用一个由三个RBM分量组成的DBN-RBM从ICA处理的fMRI中提取显著特征,最终在四个公共数据集上实现了90%以上的F1平均测量值。
实验2:DBN-RBM和DBN-AE检测阿尔茨海默病
实验3:应用D-AE模型从静止状态的fMRI数据中提取潜在特征,用于诊断轻度认知功能障碍(MCI)。-
将潜在特征输入支持向量机分类器,识别率达到72.58%。
自然图像的重建引起广泛的关注。
实验1:从fMRI中重建视觉刺激的深卷积GAN,
发生器包含四个卷积层,以便将输入的fMRI转换为自然图像。
用于测量由大脑中神经元的电活动引起的磁场。通过磁变化反映大脑活动
实验1:致力于通过去除诸如眨眼和心脏活动等伪影来细化MEG信号。
最后,该方法在局部数据集上的灵敏度达到85%,特异性达到97%。
实验2:目标同实验1
基于深度学习的大脑信号系统主要用于检测和诊断精神疾病,如睡眠障碍、阿尔茨海默病、癫痫发作等。
睡眠障碍:
对于睡眠障碍的检测,大多数研究都集中在基于睡眠自发脑电图的睡眠阶段检测上。DBN-RBM和CNN被广泛应用于特征选择和分类。
阿尔茨海默病:
功能磁共振成像在阿尔茨海默病的诊断中有着广泛的应用。优点是高空间分辨率,几项研究的诊断准确率均在90%以上。
癫痫:
癫痫发作的检测主要基于自发脑电图。流行的深度学习模型包括独立的CNN和RNN,以及结合RNN和CNN的混合模型
例如,将D-AE应用于特征提取,然后将支持向量机应用于癫痫诊断
研究人员已经证明了深度学习模型在检测大量精神疾病方面的有效性,如抑郁症[113]、发作间期癫痫放电(IED)[230]、精神分裂症[211]、克雅氏病(CJD)[123]和轻度认知障碍(MCI)
随着物联网的发展,越来越多的智能环境可以连接到大脑信号。
例如,辅助机器人可用于智能家居,其中机器人可以由个体的大脑信号控制。
基于视觉刺激的自发EEG和fNIRS信号的机器人控制问题。
P300 speller,深度学习模型使大脑信号系统能够从非300片段中识别出P300片段
使用一种结合RNN、CNN和AE的混合模型,从MI-EEG中提取信息特征来识别用户想要说的字母。
应用于身份识别和身份验证
前者通过多类别分类来识别一个人的身份[6]。后者进行二元分类来决定一个人是否被授权
个性化信息(如多媒体内容)检索或智能人机界面设计
试图根据脑电图信号,使用深度学习算法(如CNN及其变体)将用户的情绪状态分为两类(积极/消极)或三类(积极、中性和消极)
DBN-RBM是从情绪自发脑电图中发现隐藏特征的最具代表性的深度学习模型
一般情况下,如果驾驶员的反应时间小于0.7秒,则认为驾驶员处于警戒状态;如果反应时间大于2.1秒,则认为驾驶员处于疲劳状态。
目前,基于EEG的驾驶困倦可以得到较高的识别率(82%∼95%)
适当的心理负荷对于维持人类健康和预防事故是必不可少的。
持续脑电来评估操作者的心理负荷,以警告随着时间,操作者的性能下降。
通过一个循环卷积框架研究了跨多个心理任务的心理负荷测量。该模型同时从空间、频谱和时间维度学习脑电特征,二值分类(高/低负荷水平)的准确率为88.9%
推荐系统,紧急刹车,视觉对象识别,内疚测试,隐藏信息测试,区分性别。
https://en.wikipedia.org/wiki/Self-driving_car https://physionet.org/physiobank/database/sleep-edfx/ https://massdb.herokuapp.com/en/ https://physionet.org/pn3/shhpsgdb/ https://physionet.org/pn6/chbmit/ https://www.isip.piconepress.com/projects/tuh.eeg/html/downloads.shtml https://physionet.org/pn4/eegmmidb/ http://www.bbci.de/competition/ii/ http://www.eecs.qmul.ac.uk/mmv/datasets/amigos/readme.html http://bcmi.sjtu.edu.cn/seed/download.html https://www.eecs.qmul.ac.uk/mmv/datasets/deap/ https://owenlab.uwo.ca/research/the.openmiir.dataset.html http://adni.loni.usc.edu/data-samples/access-data/ https://www.med.upenn.edu/sbia/brats2018/data.html
第六节,分析和指南,根据大脑信号选择适当的模型
70%的EEG论文关注自发EEG(133种出版物)。自发的脑电图分成几个方面:睡眠、运动想象、情绪、精神疾病、数据增强和其他。
睡眠:总共19篇,6篇使用CNN,2篇RNN,还有3种RNN+CNN的混合模型。
运动想象:广泛使用CNN和基于CNN的混合模型。表示型模型常用DBN-RBN提取潜在特征。
情绪:总共25篇,超过一半使用表示模型(D-AE,D-RBM,DBN-RBM)。最典型的状态识别工作将用户的情绪识别为积极、中立或消极。进一步对配价和唤起率进行分类
精神疾病:大部分相关研究集中在癫痫发作和阿尔茨海默病的检测上。大部分相关研究集中在癫痫发作和阿尔茨海默病的检测上。许多研究可以达到90%以上的高准确率。在这一领域,标准的CNN模型和D-AE是普遍存在的。一个可能的原因是CNN和AE是最著名和最有效的深度学习模型的分类和降维
数据增强:基于GAN的数据扩充
其他:大约有30个研究正在调查其他自发脑电图,如驾驶疲劳、视听刺激冲击、认知/心理负荷和眼睛状态检测。这些研究广泛应用标准CNN模型和变体。
视觉诱发电位(VEP)引起大量研究(21篇)。6种混合模型。
快速连续视觉表示(RSVP),只有CNN算法。
fNIRS图像的研究很少采用深度学习的方法,主要的研究只是采用简单的MLP模型。我们认为,由于fNIRS具有高便携性和低成本的特点,应引起更多的关注。
至于功能磁共振成像,有23篇论文提出了深度学习的分类模型。CNN模型因其在图像特征学习中的突出表现而被广泛应用。
6.2 深度学习模式的选择标准
结论1:大多数采用判别模型。
结论2:超过70%的判别性模型都采用了CNN及其变体,为此我们提供了以下原因:
首先,CNN的设计足够强大,能够从EEG信号中提取潜在的鉴别特征和空间相关性进行分类。因此,有些研究采用CNN结构进行分类,而有些研究则采用CNN结构进行特征提取。
CNN在一些研究领域(如计算机视觉)取得了巨大的成功,更容易找到代码。
一些脑信号图(如功能磁共振成像)是自然形成的二维图像,有利于CNN进行处理。
结论3:表示模型中,DBN,尤其是DBN-RBM是最常用的特征提取模型。原因有二:
【大多数采用DBN-RBM模型的作品都是在2016年之前出版的。可以推断,在2016年之前,研究人员更倾向于使用DBN进行特征学习,然后使用非深度学习分类器;但最近,越来越多的研究希望采用CNN或混合模型进行特征学习和分类。】
结论4:生成模型很少独立使用,基于GAN和VAE的数据增强和图像重建主要集中在fMRI和EEG信号上,有前途。
结论5:53篇论文中,RNN和CNN的组合约占五分之一,结合后具有很好的时空特征提取能力。
结论6:表示模型+判别模型也很常用,28篇中有这种方法,所采用的表示模型多为AE或DBN-RBM,同时所采用的判别模型多为CNN。
将脑信号分析应用于医疗领域是目前最吸引人和最热门的领域。
一般来说,大多数深度学习算法在多个睡眠阶段场景下都能达到85%以上的准确率。
对于fMRI图像,CNN在网格化空间信息学习方面具有很大的优势,使其获得了非常全面的分类准确率(90%以上)。
至于癫痫发作,一般是根据脑电图信号进行诊断。单一的RNN分类器(如LSTM或GRU)由于其良好的时间依赖性表示能力,似乎比其对应的分类器工作得更好。
检测阿尔茨海默病的一个关键方法是通过测量大脑特定区域的功能来分析大脑信号。具体来说,可以通过自发的脑电图信号或功能磁共振成像来进行诊断
由于视觉诱发电位明显且易于检测,许多研究都集中在VEP信号上。一个重要的数据来源是来自第三届BCI竞赛。
脑电信号具有较高的时间分辨率,能够捕捉快速变化的情绪。因此,几乎所有的研究都是基于自发的脑电信号。这些信号是在被试观看视频时收集的,视频被认为是激发受试者特定情绪的。主要是使用层次化CNN,DBN-RBM结合强分类器,前一种更好。
一般框架需要两个关键能力:注意机制和捕捉潜在特征的能力。前者保证了框架能够集中于输入信号中最有价值的部分,而后者使框架能够捕捉到与众不同和信息丰富的特征。
方法2:CNN是最适合捕捉不同层次和范围特征的结构。未来,CNN可以作为一种基本的特征学习工具,并与适当的注意机制相结合,形成一个通用的分类框架。
方法1:可以考虑如何解释由深层神经网络导出的特征表示,学习的特征与任务相关的神经模式或精神障碍的神经病理学之间的内在关系。
方法1:实现这一目标的一个可能的解决方案是建立一个个性化的迁移学习模型。
个性化情感模型可以采用转换参数传递的方法来构造个体分类器,并学习映射数据分布和分类器参数之间关系的回归函数
方法2:从输入数据中挖掘与主题无关的组件。输入的数据可以分解为两部分:一个依赖于主题的主题相关组件和一个所有主题都通用的主题无关组件。一个混合多任务模型可以同时处理两个任务,一个侧重于人的识别,另一个侧重于类识别。在类识别任务中,需要一个训练良好、收敛良好的模型来提取与主题无关的特征。
Adversarial V ariational Embedding (对抗性变异嵌入)-----> 高质量生成模型
有两种方法可以增强无监督学习:
一种是利用众包(给大众志愿者)方法对未标记的观测值进行标记;
另一种是利用无监督域自适应学习,通过线性变换来调整源脑信号和目标信号的分布
在真实场景中,大脑信号系统需要接收实时的数据流并实时产生分类结果
由于受试者注意力不集中和设备固有的不稳定性(例如采样率波动)等诸多因素,采集到的实时信号更具噪声和不稳定性。通过我们的实验,在线脑信号系统的准确率通常比同类系统低10%。
方法:投票和聚合来平均多个连续样本的结果,提高解码性能。
脑电采集设备主要有三种:不便携头戴式、便携式头戴式和耳式脑电传感器。
第一种,采样频率高,信道数多,信号质量高,但价格昂贵。适合医院体检。
第二种,(例如Neurosky、Emotiv EPOC),有1∼14个通道和128∼256采样率,但读数不准确,长期使用后会造成不适。
第三种,还在实验室阶段。EEGrids是唯一商业化的耳脑电设备。
受限玻尔兹曼机 RBN(2000年后流行)
RBM可以看做是一个编码解码的过程,从可见层到隐藏层就是编码,反之是解码。对于每个训练样本, 期望编码解码后的可见层输出和之前可见层输入的差距尽量的小。
RBM详细推导过程:https://www.cnblogs.com/pinard/p/6530523.html
深度波尔茨曼机Deep Boltzmann Machine (DBM)
RBN实现的深度置信网络 (DBN-RBN)
与DBM的区别是隐藏层之间为单向的。优化计算更简单。
降噪自编码器(D-AE)
DAE(Denoising Autoencoder)的核心思想是,一个能够从中恢复出原始信号的神经网络表达未必是最好的,能够对“损坏”的原始数据编码、解码,然后还能恢复真正的原始数据,这样的特征才是好的。
卷积神经网络(CNN)
循环神经网络(RNN)
长短期记忆(LSTM)
评价标准